
type
status
date
slug
summary
tags
category
icon
password
MySQL 中 SELECT 语句执行流程
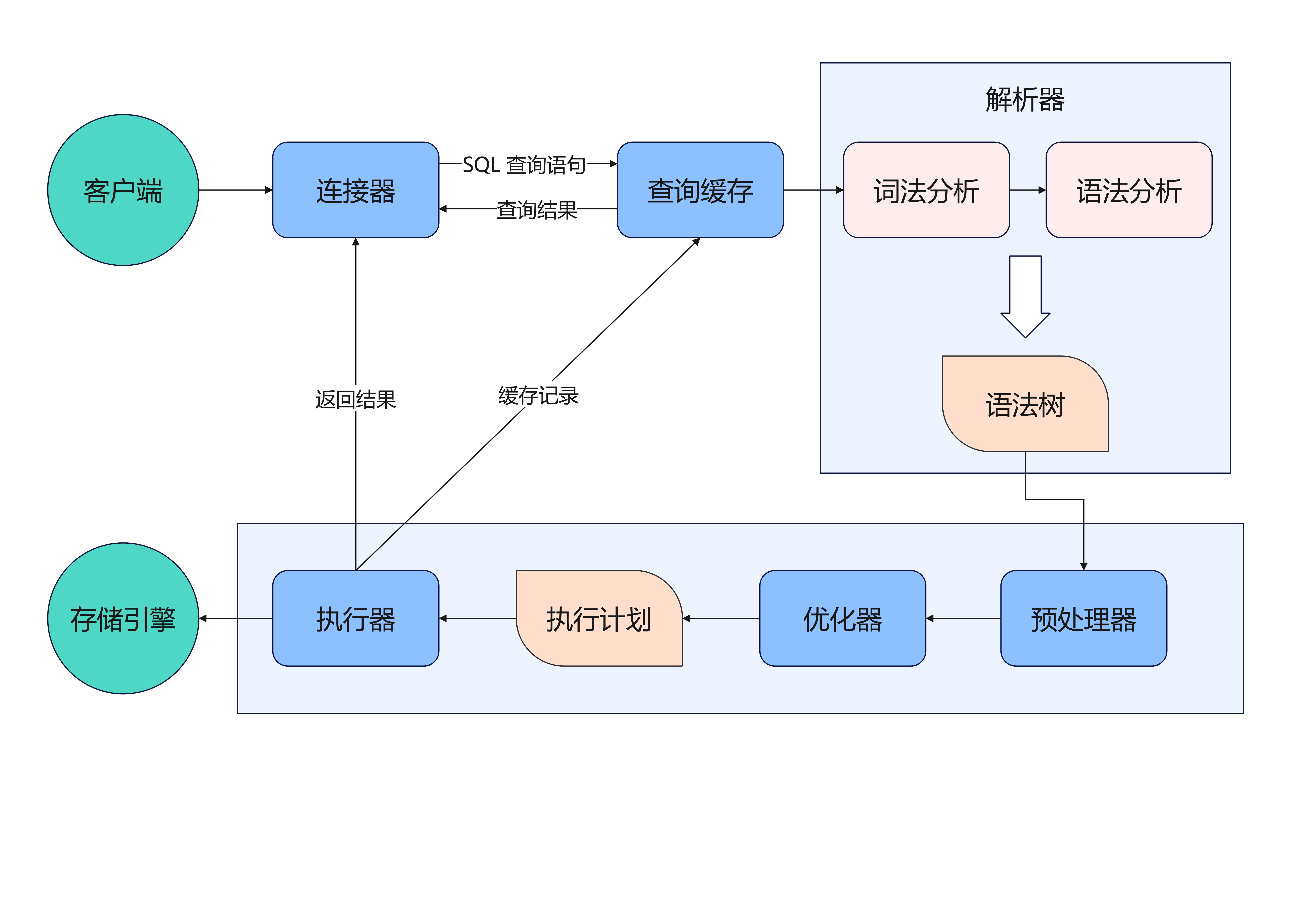
第一步:连接器
连接器工作如下:
- 与客户端进行 TCP 三次握手建立连接
- 校验客户端的用户名和密码,如果用户名或密码不对,则会报错
- 如果用户名和密码都对了,会读取该用户的权限,然后后面的权限逻辑判断都基于此时读取到的权限
第二步:查询缓存(8.0后移除)
在连接器完成工作之后,如果 MySQL 服务接收到客户端发来的 SQL 语句之后,就会尝试解析出 SQL 语句的第一个字段,来判断该 SQL 语句的类型。
在 MySQL 8.0 版本之前,如果是查询语句(SELECT),那么 MySQL 就会先去查询缓存(Query Cache)中查找缓存数据。
查询缓存存储的形式是 key-value 形式,即 SQL 查询语句 - SQL 语句查询结果。
如果命中查询缓存,那么就会直接从查询缓存中取出 value 值返回给客户端,反之则继续执行之后的步骤,并将最后的结果存入查询缓存中。
但当一张表执行了其他非查询操作,这张表的所有查询缓存都会被清空。因此对于更新较为频繁的表来说,查询缓存并没有起到太大的作用,所以在 MySQL 8.0 之后,查询缓存被官方删除了。
第三步:解析器
在执行 SQL 语句之前, MySQL 会对该语句做词法分析和语法分析。
1.词法分析
MySQL 会从传过来的字符串中识别出关键字来,例如
在分析之后,会得到 4 个 token,其中包含两个 keyword(SELECT, FROM)
关键字 | 非关键字 | 关键字 | 非关键字 |
SELECT | id | FROM | user |
2.语法分析
根据词法分析的结果,语法解析器会根据语法规则,判断该语句是否满足 MySQL 语法,如果没问题就构建出 SQL 语法树,这样方便后面的模块获取 SQL 类型、表名、字段名、WHERE 条件等等。
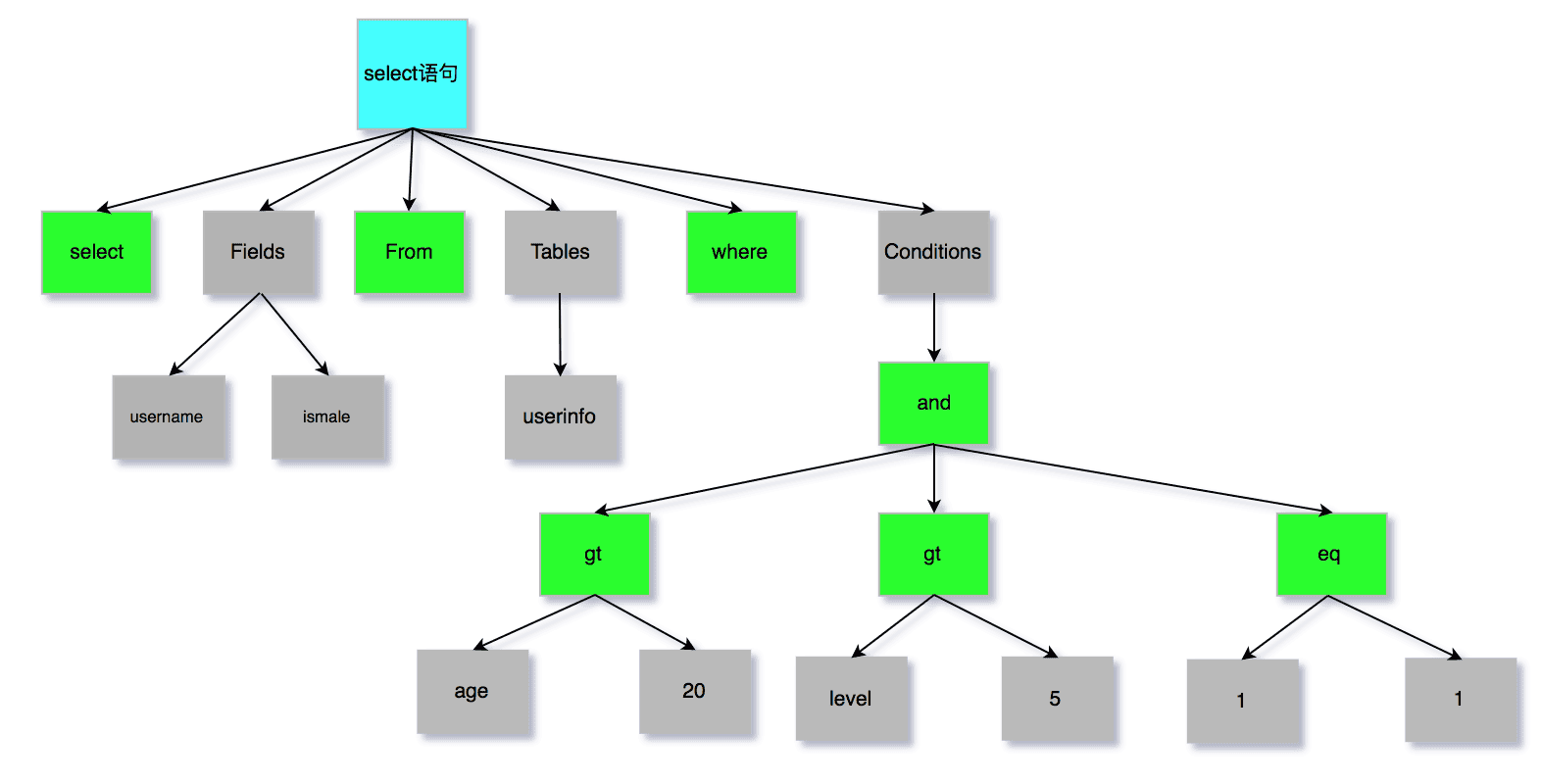
如果此时解析器发现 SQL 语句的语法不对,就会在这个阶段报错。
注意:表不存在或者字段不存在,并不是在解析器里做的。《MySQL 45 讲》说是在解析器做的,但是从 MySQL 源码(5.7和8.0)中得出结论是解析器只负责检查语法和构建语法树,但是不会去查表或者字段存不存在。
第四步:执行 SQL
执行器主要分为下面三个阶段:
- prepare 阶段 — 预处理阶段
- optimize 阶段 — 优化阶段
- execute 阶段 — 执行阶段
预处理阶段
预处理阶段主要执行下面事件;
- 检查 SQL 查询语句中的表或者字段是否存在
- 将
select *中的符号,扩展为表上的所有列
优化阶段
优化阶段中,优化器会为 SQL 语句制定一个执行计划,就是将 SQL 语句的执行方案确定下来。例如在表中有多个索引的时候,优化器会基于查询成本的考虑来决定使用哪个索引。
例如对于 user 表,它具有主键索引(id)和普通索引(name),执行如下 SQL 语句:
那么这条 SQL 语句即可以使用主键索引,也可以使用普通索引,但查询成本并不相同,就会由优化器来具体决定。
不过很显然的是,这条查询语句是覆盖索引,可以直接在二级索引中查找到结果,查询主键索引的开销更大,所以优化器会选择查询普通索引(name)。

执行阶段
确定完执行方案之后,MySQL 就通过执行器来和存储引擎进行交互,交互以记录为单位。
主键索引查询
这条查询语句的查询条件用到了主键索引,而且是等值查询,同时主键 id 是唯一,不会有 id 相同的记录,所以优化器决定选用访问类型为 const 进行查询,也就是使用主键索引查询一条记录,那么执行器与存储引擎的执行流程是这样的:
- 执行器第一次查询,会调用 read_first_record 函数指针指向的函数,因为优化器选择的访问类型为 const,这个函数指针被指向为 InnoDB 引擎索引查询的接口,把条件
id = 1交给存储引擎,让存储引擎定位符合条件的第一条记录。
- 存储引擎通过主键索引的 B+ 树结构定位到 id = 1的第一条记录,如果记录是不存在的,就会向执行器上报记录找不到的错误,然后查询结束。如果记录是存在的,就会将记录返回给执行器;
- 执行器从存储引擎读到记录后,接着判断记录是否符合查询条件,如果符合则发送给客户端,如果不符合则跳过该记录。
- 执行器查询的过程是一个 while 循环,所以还会再查一次,但是这次因为不是第一次查询了,所以会调用 read_record 函数指针指向的函数,因为优化器选择的访问类型为 const,这个函数指针被指向为一个永远返回 -1 的函数,所以当调用该函数的时候,执行器就退出循环,也就是结束查询了。
全表扫描
这条查询语句的查询条件没有用到索引,所以优化器决定选用访问类型为 ALL 进行查询,也就是全表扫描的方式查询,那么这时执行器与存储引擎的执行流程是这样的:
- 执行器第一次查询,会调用 read_first_record 函数指针指向的函数,因为优化器选择的访问类型为 all,这个函数指针被指向为 InnoDB 引擎全扫描的接口,让存储引擎读取表中的第一条记录;
- 执行器会判断读到的这条记录的 name 是不是 张三,如果不是则跳过;如果是则将记录发给客户的(是的没错,Server 层每从存储引擎读到一条记录就会发送给客户端,之所以客户端显示的时候是直接显示所有记录的,是因为客户端是等查询语句查询完成后,才会显示出所有的记录)。
- 执行器查询的过程是一个 while 循环,所以还会再查一次,会调用 read_record 函数指针指向的函数,因为优化器选择的访问类型为 all,read_record 函数指针指向的还是 InnoDB 引擎全扫描的接口,所以接着向存储引擎层要求继续读刚才那条记录的下一条记录,存储引擎把下一条记录取出后就将其返回给执行器(Server层),执行器继续判断条件,不符合查询条件即跳过该记录,否则发送到客户端;
- 一直重复上述过程,直到存储引擎把表中的所有记录读完,然后向执行器(Server层) 返回了读取完毕的信息;
- 执行器收到存储引擎报告的查询完毕的信息,退出循环,停止查询。
索引下推
索引下推能够减少二级索引在查询时的回表操作,提高查询的效率,因为它将 Server 层部分负责的事情,交给存储引擎层去处理了。
例如 user 表如下

对 age 和 city 字段建立了联合索引(age,city):
联合索引当遇到范围查询 (>、<) 就会停止匹配,也就是 age 字段能用到联合索引,但是 reward 字段则无法利用到索引。
那么,不使用索引下推(MySQL 5.6 之前的版本)时,执行器与存储引擎的执行流程是这样的:
- Server 层首先调用存储引擎的接口定位到满足查询条件的第一条二级索引记录,也就是定位到 age > 20 的第一条记录;
- 存储引擎根据二级索引的 B+ 树快速定位到这条记录后,获取主键值,然后进行回表操作,将完整的记录返回给 Server 层;
- Server 层在判断该记录的 city 是否等于 浙江,如果成立则将其发送给客户端;否则跳过该记录;
- 接着,继续向存储引擎索要下一条记录,存储引擎在二级索引定位到记录后,获取主键值,然后回表操作,将完整的记录返回给 Server 层;
- 如此往复,直到存储引擎把表中的所有记录读完。
可以看到,没有索引下推的时候,每查询到一条二级索引记录,都要进行回表操作,然后将记录返回给 Server,接着 Server 再判断该记录的 city 是否等于 浙江。
而使用索引下推后,判断记录的 city 是否等于 浙江 的工作交给了存储引擎层,过程如下 :
- Server 层首先调用存储引擎的接口定位到满足查询条件的第一条二级索引记录,也就是定位到 age > 20 的第一条记录;
- 存储引擎定位到二级索引后,先不执行回表操作,而是先判断一下该索引中包含的列(city 列)的条件(reward 是否等于 浙江)是否成立。如果条件不成立,则直接跳过该二级索引。如果成立,则执行回表操作,将完成记录返回给 Server 层。
- Server 层在判断其他的查询条件(本次查询没有其他条件)是否成立,如果成立则将其发送给客户端;否则跳过该记录,然后向存储引擎索要下一条记录。
- 如此往复,直到存储引擎把表中的所有记录读完。
可以看到,使用了索引下推后,虽然 city 列无法使用到联合索引,但是因为它包含在联合索引(age,city)里,所以直接在存储引擎过滤出满足 city = 浙江 的记录后,才去执行回表操作获取整个记录。相比于没有使用索引下推,节省了很多回表操作。
当你发现执行计划里的 Extr 部分显示了 “Using index condition”,说明使用了索引下推。

参考资料:
- 作者:Tuwilt
- 链接:https:/blog.tuwilt.top/article/cc09635a-fbd8-4a78-ab90-08092f0a90c0
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。